

Погружаемся в продвинутые методы: заставляем модель рассуждать пошагово, структурируем её ответы и отлавливаем галлюцинации. Учимся разбивать документы на смысловые чанки и запускаем LLM прямо у себя на ноутбуке — без облаков и API.
Недавно команда Anthropic (создатели Claude) выпустила статью Building Effective Agents.
Вот несколько важных мыслей из неё:
Вывод: LLM — это строительный блок. Настоящий агент — это архитектура + оркестрация. В этом помогает Directual.
Когда вы хотите, чтобы ассистент возвращал не просто текст, а структурированные данные, нужно использовать Structured Output.
Это может быть JSON, XML, markdown, таблица и т.д.
Есть два подхода как настроить SO на платформе Directual
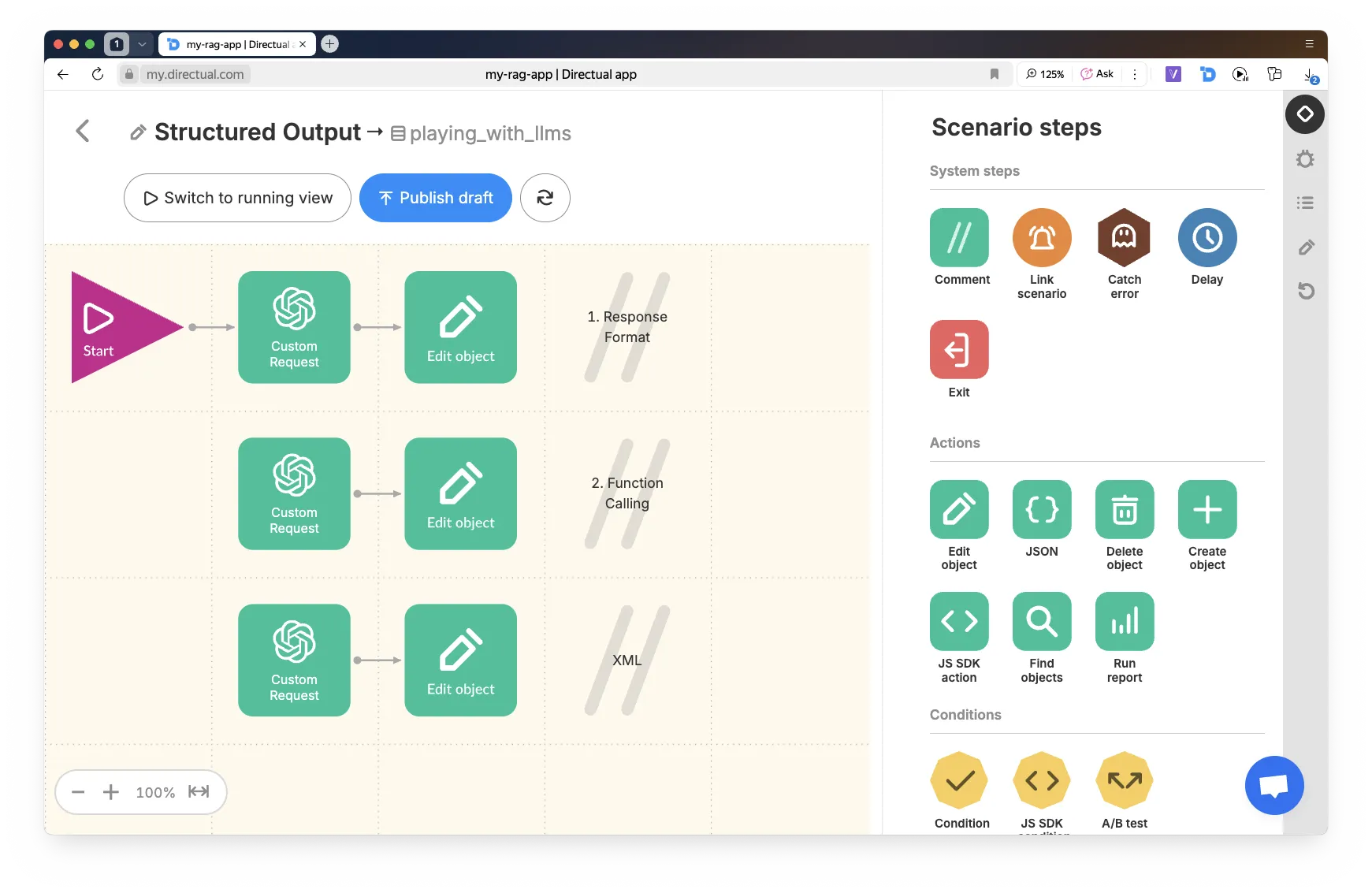
Это вариант, когда мы добавляем в запрос "response_format": { "type": "json_object" }, а стурктуру ответа указываем прямо в системном промпте. Код запроса ниже:
Этот вариант подразумевает использование tools. Формат ответа в этом случае гарантирован. Код запроса ниже:
Если нужен другой формат (например, XML) — указывается прямо в тексте промпта.
Chain of Thought (CoT) — техника, где модель размышляет пошагово. Это:
Можно хранить рассуждения для логов, а пользователю показывать только результат.
Пример CoT + SO в запросе из Directual:
На выходе мы получаем JSON вида, с которым уже можно работать далее в сценарии:
Когда документов становится много и они длинные — нужно делить их на чанки.
В Directual удобно сделать чанкинг в три шага:
{ "chunks": [ { "text" : "..." }, { "text": "..." },... ] }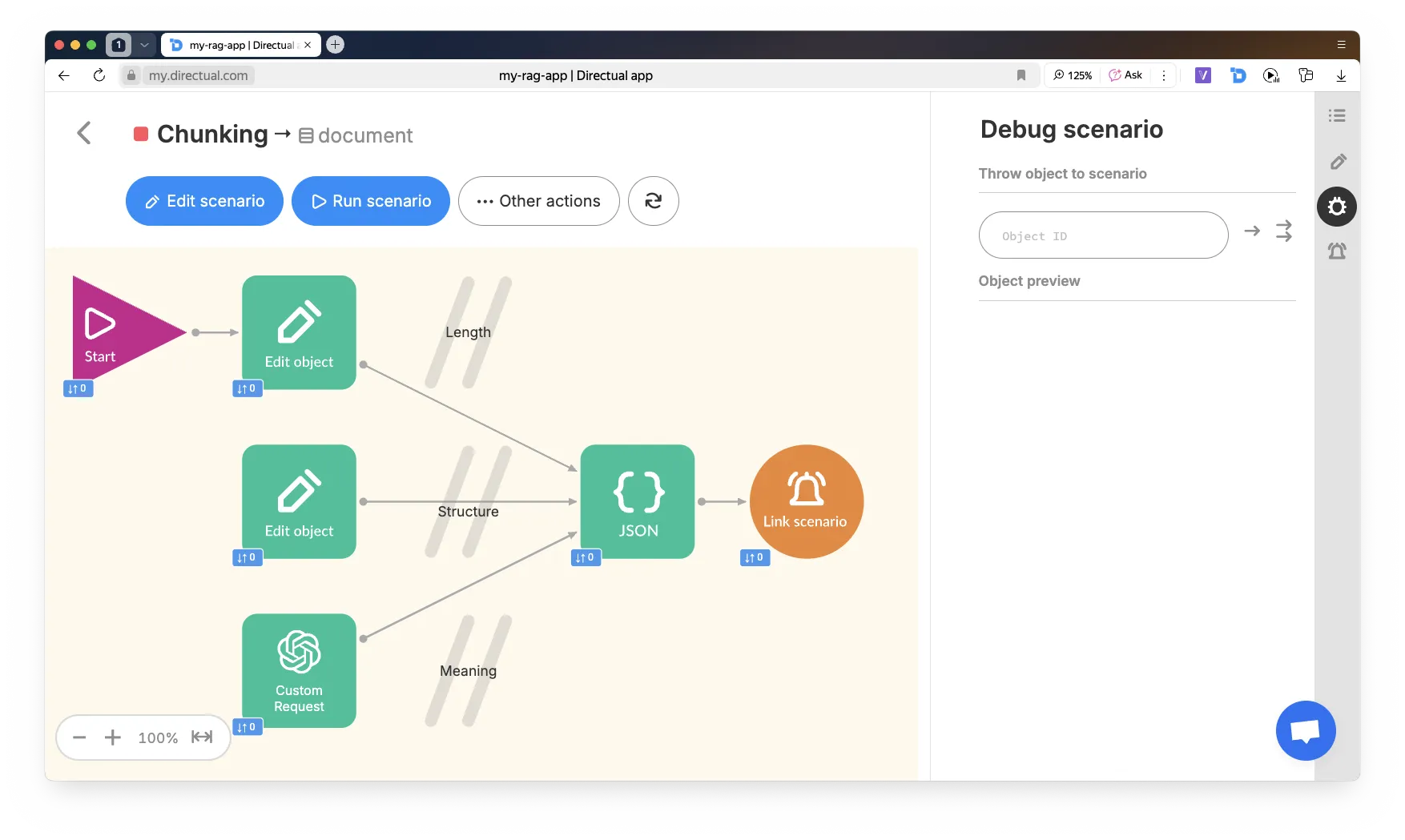
Есть три метода разбиения текста на чанки:
Например, 100 слов, с overlap 10
Код для создания JSON ниже.Обратите внимание, что для использования стрелочных функций необходимо в шаге START => Advanced включить ECMAScript 2022 (ES13), по умолчанию работает ES6. Также при сохранении JS-объекта в поле типа json необходимо оборачивать выражение в JSON.stringify().
Плохой чанкинг = однотипные ответы, обрывы логики, "ничего не найдено".
Разделяем на абзацы. Если чанк менее 5 слов, склеиваем его со следующим, потому что, скорее всего, это заголовок.
Код для шага Edit object:
Делаем запрос в ChatGPT:
Плохой чанкинг = однотипные ответы, обрывы логики, "ничего не найдено".
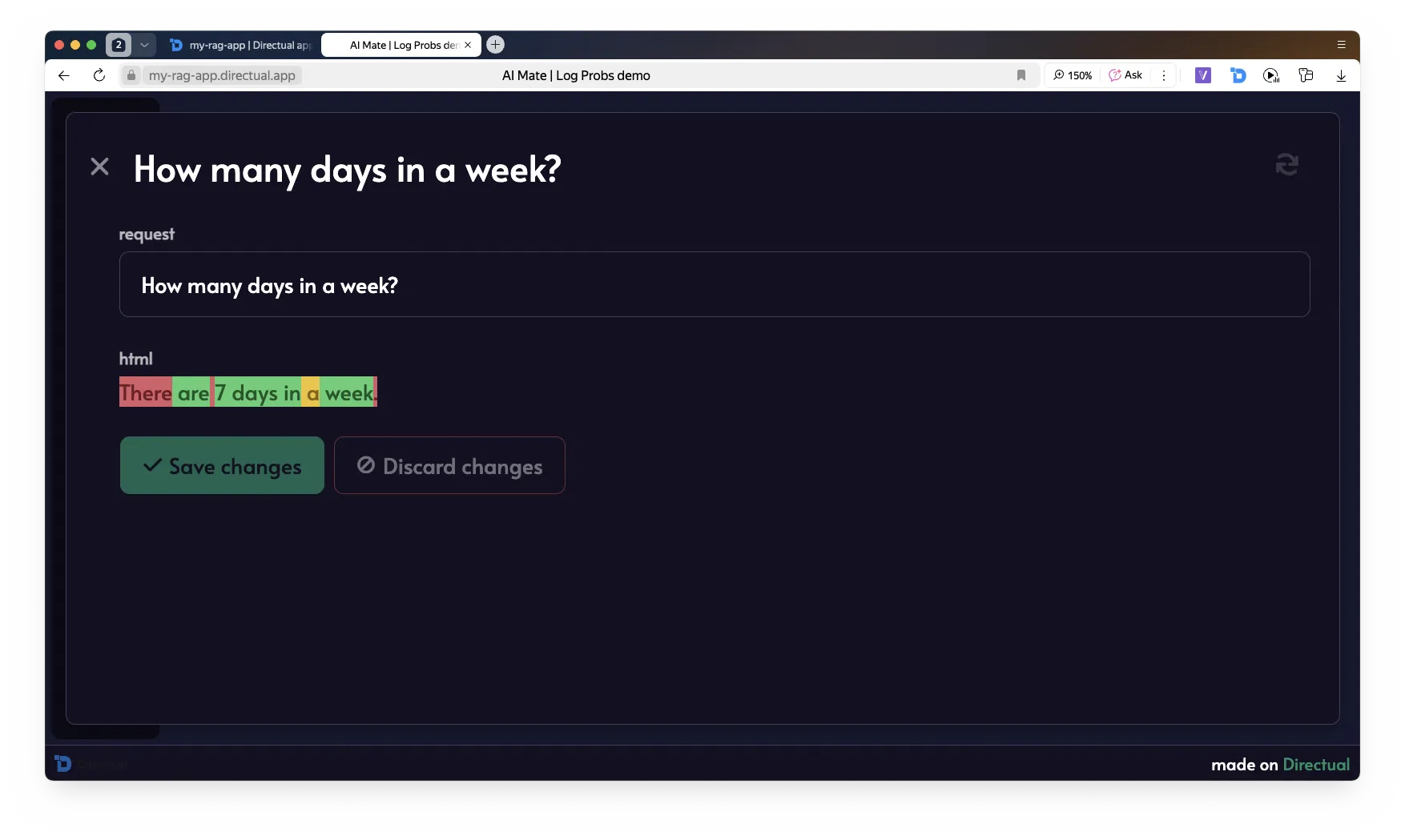
Logprobs = log-вероятность каждого токена.
Используем это для фильтрации ненадёжных ответов.
В связке с Structured Output — можно проверять уверенность по конкретным полям.
На Directual делаем:
logprobs: trueКод для визуализации ответа модели с logprobs: true:
Этот код генерирует HTML. Дополнительно в разделе Web-app => Custom code надо сохранить CSS:
Модель: Qwen 1.5 1.8B Chat — небольшая модель, но для демонстрации на ноутбуке будет достаточно!
torch — движок PyTorch, на котором работает Qwentransformers — библиотека Hugging Face для загрузки и работы с LLMaccelerate — помогает автоматически определить, есть ли GPU и ускорить инференсflask — минималистичный фреймворк для API, на нём мы поднимем наш серверЭто своего рода GitHub, но для моделей и нейросетей. Qwen там и хранится.
Далее идем на https://huggingface.co/ и входим в свой аккаунт (регистрируемся при необходимости) и создаем новый Read-only токен.
Возвращаемся в терминал и логинимся в HF, вводим свой новый токен.
Теперь сделаем первую проверку, что всё работает.
Открываем Jupyter Notebook — это такая легковесная интерактивная среда, в которой удобно писать и запускать Python-проекты по шагам.
Если не установлен — поставьте через
Создаем файл test_qwen.py
Запускаем в терминале
Модель может скачиваться до 10-15 минут. Далее она будет храниться локально, и ее можно будет использовать.
Проверили, что модель работает и отвечает, теперь сделаем сервер, который будет предоставлять нам API, идентичное ChatGPT API.
Создаем файл app.py
Запускаем!
Теперь у нас есть локальное апи, но надо сделать его доступным из интернета, в частности из Directual.
Регистируем аккаунт на ngrok.com, получаем токен и запускаем в терминале:
Полученный API можно использовать в шаге HTTP-запроса из Directual точно так же как любое другое API LLM-модели!
Вы узнали:
А главное — как всё это соединяется на Directual.
Дальше — только практика. Применяйте знания, собирайте ассистентов, делайте своих агентов. Удачи!
Заходите в наше комьюнити: помощь по проектам, знакомства с потенциальными сооснователями, общение с разработчиками платформы и не только.



