



Как мы построили нишевого ИИ-агента, который пишет живые персонализированные ответы на отзывы и вопросы Ozon, Wildberries, Яндекс Маркета и Avito. Prompt-driven архитектура, SSE-стриминг, детерминистический пре-анализатор на Python, биллинг и оркестрация — всё на Directual, без кастомного бэкенда.

Отвечатор — нишевый ИИ-агент, который пишет живые персонализированные ответы на отзывы и вопросы покупателей на Ozon, Wildberries, Яндекс Маркете и Avito. В этом кейсе мы разбираем, как устроен агент внутри: почему мы выбрали prompt-driven архитектуру вместо модного agentic loop, как работает детерминистический пре-анализатор на Python, и почему Directual закрыл сразу весь бэкенд — оркестрацию, базу данных, SSE-стриминг, права, биллинг и интеграции с маркетплейсами.
На российских маркетплейсах — Ozon, Wildberries, Яндекс Маркет, Avito — каждый день появляются миллионы отзывов. Продавцы обязаны на них отвечать: от скорости и качества ответов зависит рейтинг карточки, позиции в выдаче и, в конечном счёте, продажи.
Проблема в том, как продавцы отвечают. Мы проанализировали тысячи ответов — и увидели одну и ту же картину: 70–80% ответов — это копипаста. Один шаблонный текст на все отзывы подряд, от пятизвёздочной похвалы до разгромной единицы. «Благодарим Вас за проявленное доверие и высокую оценку нашего товара» — сотни раз, на каждый отзыв, дословно.
Покупатели это видят. Маркетплейсы это видят. Конверсия падает.
Умный ИИ-агент решает эту проблему. Отвечатор — ИИ-агент, который пишет живые, персонализированные ответы на отзывы. Не шаблоны, не болванки — а ответы, которые звучат так, будто продавец реально прочитал отзыв и реально подумал. Потому что за продавца это делает агент, который знает всё: товар, политики магазина, типичные проблемы, стиль общения, историю ответов.
В этом кейсе мы разберём, как Отвечатор устроен внутри, почему мы выбрали prompt-driven архитектуру вместо модного agentic loop, и как Directual стал инфраструктурной основой для всего этого.
Первый вопрос, который задаёт каждый: «А зачем отдельный продукт, если можно просто скормить отзыв в ChatGPT и получить ответ?»
Можно. И результат будет ожидаемый — одноразовый, без контекста, без понимания бизнеса. Вот конкретные причины, почему голая модель не работает для задачи ответов на отзывы:
ChatGPT не знает вашу политику возвратов, гарантийные условия, ассортимент, историю проблем с конкретным товаром. Он не знает, что 18% отзывов на эту модель кроссовок — жалобы на маломерки. Он напишет «первый раз слышим» там, где нужно сказать «да, мы знаем про эту особенность — рекомендуем брать на размер больше».
Каждый запрос в ChatGPT — это новый контекст с нуля. Вы не можете задать стиль ответов для всего магазина, не можете загрузить базу знаний, не можете настроить правила. Каждый раз вы копируете отзыв, вставляете промпт, редактируете результат, копируете обратно. При 50 отзывах в день это превращается в ад.
Модель не скажет вам: «У вас 73% ответов — одинаковая копипаста, канцелярит в каждом втором, а на негативные отзывы вы отвечаете в среднем через 28 часов — это убивает конверсию». Для этого нужен отдельный аналитический слой — и мы его построили.
Чтобы автоматизировать процесс, нужно тянуть отзывы по API, публиковать ответы по API, управлять правами, настраивать правила автопостинга. ChatGPT — это текстовое окно, а не бизнес-инструмент.
Вот почему нишевые ИИ-агенты — это рыночная ниша. Голая модель — это мозг без тела. А бизнесу нужен готовый агент с руками, ногами и памятью: с интеграциями, базой знаний, аналитикой, интерфейсом и правами доступа. Подробнее о разнице между подходами — в нашем сравнении ИИ-генерации и шаблонных автоответчиков.
Фронтенд — Next.js-приложение на базе стартового шаблона Directual. Трёхколоночный интерфейс с SSE-стримингом ответов.
Бэкенд — Directual: оркестрация всего пайплайна, интеграции с маркетплейсами, хранение данных, управление пользователями и правами.
ИИ-агент — prompt-driven архитектура: большой структурированный системный промпт + динамический контекст, который собирает бэкенд.
LLM-провайдер — GigaChat от Сбера. Под российский B2B выбор очевидный:
Пре-анализатор — отдельный Python-сервис для детерминистического анализа отзывов и ответов. Считает всё, что можно посчитать без LLM.
Разберём каждый компонент подробнее.
Фронтенд построен на Next.js + Directual Starter Template — нашем стартовом шаблоне, в котором уже есть авторизация (magic link, сброс пароля), WebSocket-подключение к Directual, SSE-стриминг и базовый дашборд.
Шаблон — это мост между вайбкодингом и серьёзным бэкендом. Фронтенд можно собирать быстро — через Cursor, через Copilot, как угодно — а вся бизнес-логика, данные, интеграции и оркестрация живут на Directual. Это принципиально отличается от подхода «всё на фронте»: здесь фронтенд тонкий, а мозги — на бэкенде.
Стек фронтенда:
Ключевое UX-решение — три колонки:
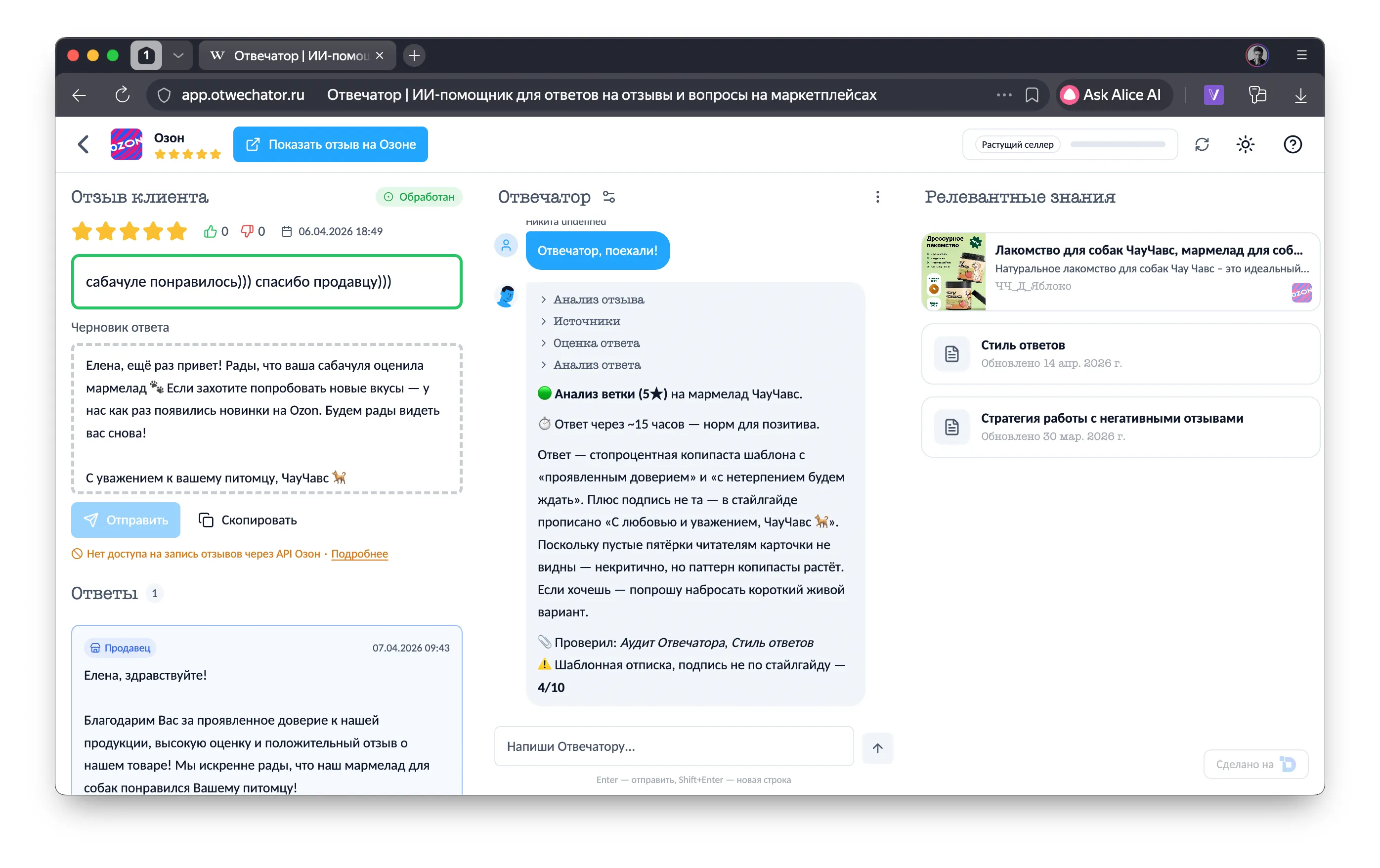
Ответ LLM стримится через SSE в реальном времени — продавец видит, как агент «думает» (extended thinking) и «печатает» ответ. Это не просто красиво — это снижает тревогу: видно, что агент работает, а не завис.
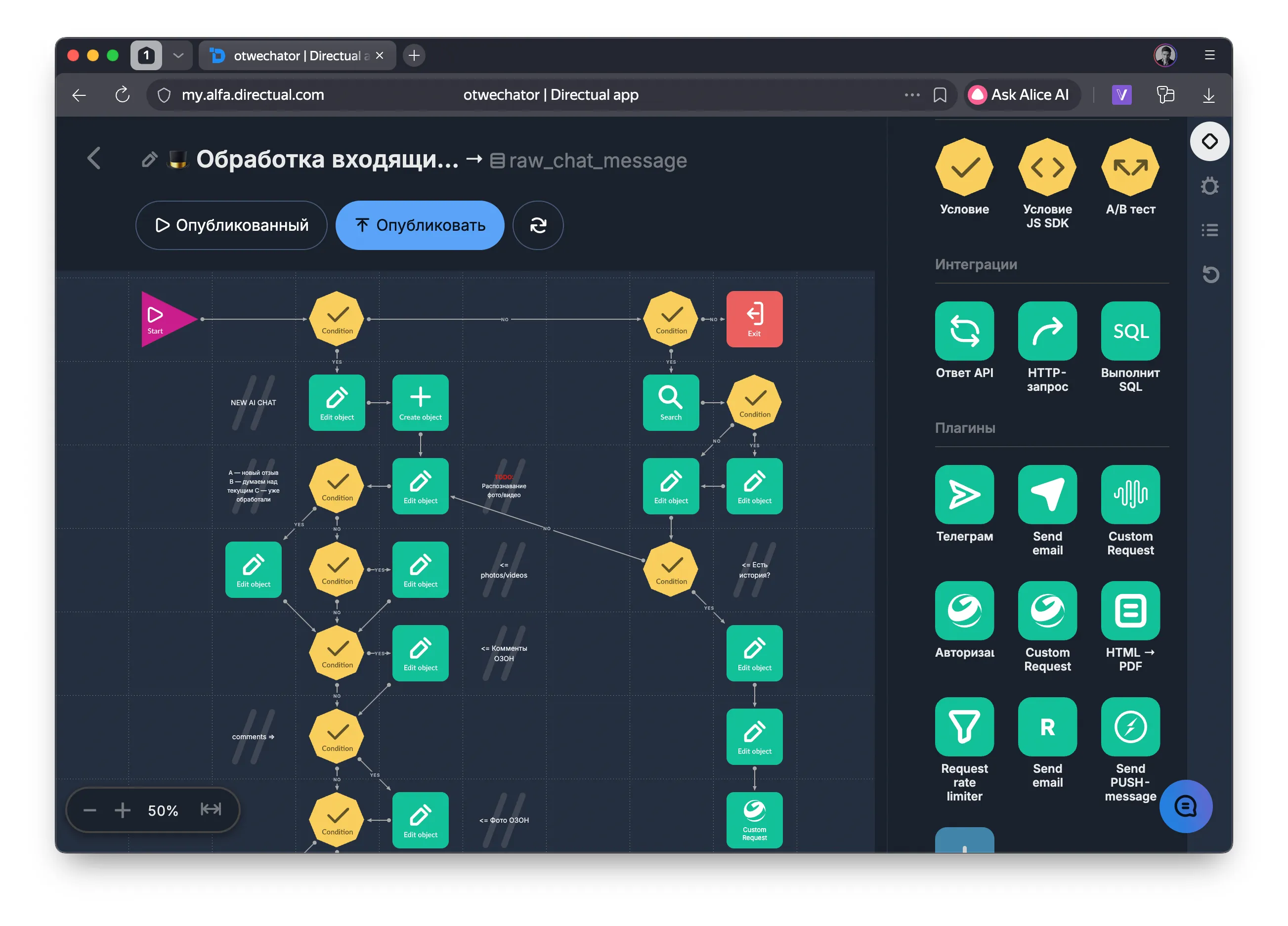
Весь бэкенд Отвечатора — это Directual. Не «Directual + ещё пять сервисов». Directual — единственная платформа, которая оркестрирует весь пайплайн от получения отзыва до публикации ответа.
Интеграции с маркетплейсами — Directual тянет отзывы по API с Ozon, Wildberries, Яндекс Маркет, Avito. Новые отзывы появляются в системе автоматически. Ответы публикуются обратно через API площадок.
Хранение данных — все отзывы, черновики, чаты, проекты, пользователи, документы — в встроенной базе данных Directual. Каждый проект — отдельный namespace с полной изоляцией данных.
Сбор контекста для LLM — при каждом запросе бэкенд собирает полный контекст: текст отзыва, комментарии, карточку товара, документы продавца, результаты пре-анализа, историю чата. Всё это упаковывается в структурированный промпт.
Вызов LLM и стриминг — Directual вызывает модель через HTTP, получает SSE-поток и проксирует его на фронтенд без буферизации.
Права и роли — встроенная система ролей контролирует, кто что может делать: кто может публиковать ответы, кто только просматривать черновики, на какие отзывы можно постить (подробнее — ниже).
Вебхуки и нотификации — новые отзывы, смена статусов, результаты анализа — всё это события, которые Directual обрабатывает через сценарии и отправляет нотификации через WebSocket.
Можно было написать бэкенд на Node.js или Python — и потратить три месяца на инфраструктуру вместо продукта. Directual позволил сосредоточиться на бизнес-логике:
Отдельно стоит рассказать про стриминг, потому что это та штука, которая отличает Directual от всего остального low-code рынка.
ИИ-агент, который молчит 10 секунд и потом выплёвывает стену текста — это плохой UX. Пользователь должен видеть, как ответ генерируется в реальном времени. Для этого нужен SSE (Server-Sent Events) — потоковая передача данных от сервера к клиенту.
Directual поддерживает SSE нативно, через directual-js-api. Причём в двух режимах — и это принципиально.
Простой вариант: отправляешь POST-запрос, в ответ получаешь SSE-поток. Запрос → стрим. Именно так работает генерация ответов в Отвечаторе: фронтенд пушит запрос, Directual собирает контекст, вызывает LLM и проксирует SSE-поток напрямую к клиенту.
Клиент → POST /stream/{structure}/{method} → Directual → LLM
◀── SSE: content_block_delta... ──◀── GigaChat stream ──◀
А вот это уже серьёзно. Двухфазный механизм:
streamIdstreamId через GETКлиент → POST /stream/init/{structure}/{method}
◀── { streamId: "abc-123" }
Клиент → GET /stream/subscribe/abc-123
◀── SSE: данные по мере готовности
Зачем два этапа? Потому что в реальных агентных системах инициатор стрима и потребитель — это часто разные процессы. Бэкенд-сценарий запускает генерацию (init), получает streamId, сохраняет его в базе — и отдельный процесс (фронтенд, другой сценарий, мобильное приложение) подписывается на результат.
Это критически важно для облачных автономных агентов. Представьте agentic loop, который крутится на сервере: агент вызывает инструмент → получает результат → думает → вызывает следующий инструмент. Каждый шаг — отдельный LLM-вызов, каждый вызов — стрим. Init + Subscribe позволяет отвязать выполнение от подключения: агент работает в фоне, а клиент может подключиться к стриму в любой момент, переподключиться после обрыва, или вообще подписаться задним числом.
Ни один low-code/no-code инструмент на рынке этого не даёт. n8n, Make, Zapier — все работают с request-response. Bubble, Xano — не поддерживают SSE вообще. Directual — единственная платформа, где стриминг LLM-ответов — нативная, продакшн-готовая функциональность с двумя режимами работы.
В Отвечаторе мы используем первый режим (single-request) — потому что у нас prompt-driven архитектура с одним вызовом. Но инфраструктура для полноценного agentic loop уже на месте, и для следующих продуктов на Directual это будет критично.
Это, пожалуй, самая интересная часть. Когда все вокруг строят agentic loops с tool calls, мы выбрали prompt-driven подход. И вот почему.
В agentic loop модель сама решает, какие инструменты вызывать: search_knowledge, get_product_info, get_similar_reviews. Звучит круто, но для задачи ответов на отзывы это overkill:
Вместо того чтобы агент сам искал информацию, бэкенд заранее собирает всё что нужно и инжектит в промпт. Модель получает полный контекст за один раз и выдаёт структурированный ответ.
┌──────────────────────────────────────────────────────┐
│ system prompt: ~600 строк инструкций (статичный) │
├──────────────────────────────────────────────────────┤
│ user message (динамический, собирается бэкендом): │
│ <task>A</task> │
│ <review>текст отзыва, рейтинг, дата...</review> │
│ <comments>история комментариев</comments> │
│ <product_contexts>карточка товара</product_contexts>│
│ <seller_docs>политики, стиль</seller_docs> │
│ <seller_analysis>аудит ответов</seller_analysis> │
├──────────────────────────────────────────────────────┤
│ assistant: структурированный ответ │
│ <review_analysis>анализ отзыва</review_analysis> │
│ <response_strategy>стратегия ответа</strategy> │
│ <draft>готовый текст ответа</draft> │
│ <chat_message>сообщение продавцу</chat_message> │
└──────────────────────────────────────────────────────┘
Системный промпт — это не «ты ассистент, отвечай на отзывы». Это детальная спецификация поведения на ~600 строк, размеченная в XML. Документ описывает:
Ключевое архитектурное решение — использование XML-тегов как протокола между LLM и интерфейсом. Модель отвечает структурированно:
<review_analysis> — анализ ситуации<sources_used> — какие документы использованы<response_strategy> — стратегия ответа<draft> — готовый текст ответа<chat_message> — сообщение продавцу в чатФронтенд парсит эти теги из SSE-потока в реальном времени и раскладывает по секциям интерфейса: черновик — налево, сообщение — в чат, анализ — в сворачиваемый блок. Это одновременно:
Каждый проект в Отвечаторе — это отдельное пространство со своей базой знаний. Продавец загружает:
Всё это хранится в базе данных Directual, и при каждом запросе бэкенд подтягивает релевантные документы и инжектит их в промпт. Агент знает ваш бизнес не потому, что «обучен» — а потому, что получает актуальный контекст при каждом вызове.
Одна из самых мощных фич — Аудит Отвечатора. Это детерминистический Python-сервис, который анализирует существующие отзывы и ответы продавца до того, как LLM начнёт работу.
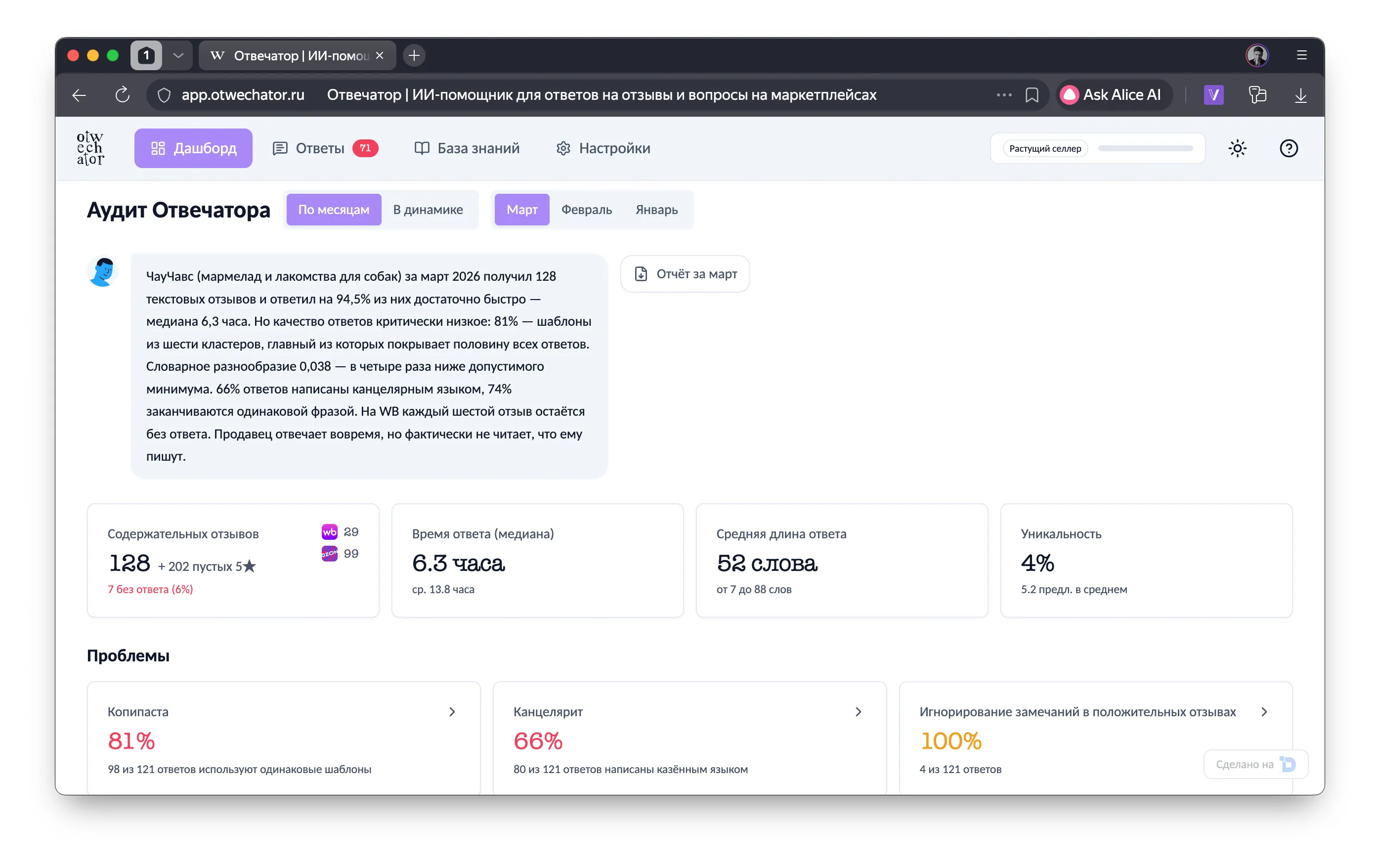
Задача: понять, как продавец отвечал раньше, найти системные проблемы, выявить антипаттерны. Это можно было бы делать в LLM — но зачем тратить токены на то, что отлично считается алгоритмически?
Пре-анализатор — это FastAPI-сервис на Python. Никаких LLM-вызовов. Всё считается локально: TF-IDF, cosine similarity, DBSCAN-кластеризация, морфологический анализ через pymorphy3. Чистая математика.
По API затягиваются отзывы и ответы продавца за последний месяц, пачкой отправляются в пре-анализатор. Он обрабатывает от 10 до 2000 пар «отзыв — ответ» и выдаёт отчёт:
12 модулей анализа:
Результат пре-анализа инжектится в промпт как <seller_analysis> — агент видит полную картину:
Благодаря этому агент не повторяет ошибки продавца. Если продавец в 73% ответов писал «Благодарим за обратную связь» — агент найдёт другую формулировку. Если жалоба на маломерки — системная (18% всех отзывов) — агент не напишет «первый раз слышим».
Результат кэшируется и переиспользуется для всех отзывов на этот товар — нет смысла пересчитывать на каждый отзыв.
Продавец открывает отзыв и жмёт «Поехали!». Дальше:
Итого: ~7–13K токенов на входе, ~1–2K на выходе. Один вызов. 2–5 секунд.
Продавец пишет в чат: «Сделай покороче» или «Добавь про гарантию» или «Убери извинения, мы не виноваты».
Бэкенд добавляет сообщение в историю чата, подставляет текущий черновик, обновляет контекст (если документы изменились) — и снова один вызов LLM. Модель видит всю историю + правку продавца и выдаёт обновлённый черновик.
Продавец уже ответил на маркетплейсе. Отвечатор анализирует ветку и даёт честную оценку по 11 критериям: скорость ответа, конкретность, краткость, канцелярит, тон, полнота, обещания, эффект для читателя, вывод в личку, копипаста, контекстуализация. Ставит оценку от 1 до 10 — без завышений.
Если оценка низкая (1–4) — предлагает follow-up комментарий, который продавец может опубликовать следом, чтобы исправить ситуацию. Не «перепиши ответ» (его уже нельзя отредактировать), а «допиши дополнение».
Одна из концепций, которой мы гордимся: Агент Отвечатор — полноправный член команды.
В проекте есть команда: владелец магазина, менеджеры, помощники. Каждому назначаются права — кто может просматривать, кто может редактировать, кто может публиковать ответы.
И вот ключевое: агент — это тоже участник с настраиваемыми правами. Он работает в тех же рамках, что и люди.
Можно настроить:
Это позволяет выстроить процесс под реальный бизнес: опытному менеджеру — больше свободы, джуниору — ограничения, агенту — свои правила. Все работают в одном интерфейсе, все подчиняются одним правилам.
| Компонент | Технология | Зачем |
|---|---|---|
| Бэкенд | Directual | Оркестрация, данные, API, интеграции, права |
| Фронтенд | Next.js + Directual Starter Template | UI, SSE-стриминг, WebSocket |
| UI-компоненты | shadcn/ui + Tailwind CSS | Быстрая сборка интерфейса |
| LLM | GigaChat (Сбер) | Российская инфраструктура, отличный русский, нет санкционных рисков, оплата в рублях |
| Пре-анализатор | Python, FastAPI, scikit-learn, pymorphy3 | Детерминистический анализ без LLM |
| Стриминг | SSE (Server-Sent Events) | Потоковая передача ответов LLM |
| Нотификации | Socket.IO | Реалтайм-обновления статусов |
При 1000 отзывов в день — $10–30 на LLM. Менеджер обходится дороже.
Для тех, кому интересны детали реализации на платформе:
Отдельная история — монетизация. Биллинг Отвечатора — это связка ЮKassa + Directual. ЮKassa принимает деньги, а вся логика учёта, подписок и балансов живёт на Directual:
ЮKassa отвечает за приём денег — всё остальное (логика подписок, балансы, списания, уведомления) живёт на Directual как обычная бизнес-логика. Никакого кастомного billing-микросервиса.
Directual автоматически генерирует REST API для каждой структуры. Фронтенд общается с бэкендом через стандартные GET/POST-запросы и SSE-стримы. Всё это работает через единую точку авторизации — никаких отдельных auth-сервисов.
Мы строим продукт на собственной платформе — и это не просто «собака ест свою еду». Directual реально закрывает все потребности Отвечатора:
Сложный бэкенд без кода — оркестрация пайплайна генерации, интеграции с четырьмя маркетплейсами, стриминг, вебхуки, CRON-задачи. Всё это — визуальные сценарии.
Подключение к любым LLM — GigaChat, YandexGPT, Claude, GPT, Gemini — через стандартные HTTP-запросы. Не привязаны к одному провайдеру, можем переключать модели в зависимости от задачи, бюджета и регуляторных требований.
Нативный SSE-стриминг — два режима: single-request для простых пайплайнов и init + subscribe для автономных агентов. Ни один конкурент в low-code это не предлагает — подробности в directual-js-api.
Биллинг как бизнес-логика — приём платежей, подписки, учёт потребления токенов и ответов — всё через сценарии и структуры данных, без внешних billing-сервисов.
Права и роли из коробки — система пермишенов, которая позволила реализовать концепцию «агент как член команды» без написания auth-логики.
Облако — не думаем о серверах. Отвечатор обрабатывает тысячи отзывов в день, Directual масштабируется автоматически.
Скорость разработки — от идеи до MVP — недели, не месяцы. Все изменения в бизнес-логике — через визуальный конструктор, без деплоев бэкенда.
Отвечатор — это пример того, что происходит, когда нишевый ИИ-агент строится на правильной инфраструктуре:
Если вы продаёте на маркетплейсах и устали от шаблонных ответов — попробуйте Отвечатор.
Если вы хотите построить своего ИИ-агента для другой ниши — начните с Directual. Бесплатный курс по ИИ-агентам — 60 минут, и вы построите первого агента с RAG-системой.

Присоединяйтесь к 22 000+ no-code-разработчиков на Directual и создавайте то, чем можно гордиться, — быстрее и дешевле, чем раньше. Начать просто благодаря визуальному UI разработки, масштабировать так же просто с enterprise-grade базами данных и бэкендом.

