

How we built a niche AI agent that writes natural, personalized replies to reviews on Ozon, Wildberries, Yandex Market and Avito. Prompt-driven architecture, native SSE streaming, a deterministic Python pre-analyzer, billing and orchestration — all running on Directual, with zero custom backend code.

Otwechator is a niche AI agent that writes natural, personalized replies to customer reviews on the marketplaces Ozon, Wildberries, Yandex Market and Avito. In this case study we walk through how the agent is built: why we picked a prompt-driven architecture over the trendy agentic loop, how a deterministic Python pre-analyzer does the heavy lifting before the LLM is ever called, and why Directual ended up powering the entire backend — orchestration, database, SSE streaming, permissions, billing and marketplace integrations.
Russian marketplaces — Ozon, Wildberries, Yandex Market, Avito — generate millions of customer reviews every day. Sellers are required to respond to them: response speed and quality directly drive product card ratings, search ranking and, ultimately, sales.
The problem is how sellers answer. We analysed thousands of replies and saw the same pattern again and again: 70–80% of them are copy-paste. One templated message stamped onto every review, from a glowing five-star to a brutal one-star: "Thank you for your trust and high appraisal of our product" — verbatim, hundreds of times in a row.
Buyers see it. The marketplaces see it. Conversion drops.
We set out to fix this. Otwechator is an AI agent that writes living, personalized replies — not templates, not fillers. The answers sound like the seller actually read the review and actually thought about it, because behind the scenes there's an agent that knows everything: the product, the store's policies, the recurring complaints, the tone of voice, the history of past replies.
In this case study we'll dig into how Otwechator is wired up under the hood, why we chose a prompt-driven architecture over the trendy agentic loop, and how Directual became the infrastructure foundation for the whole thing.
The first question we get is always: "Why a separate product? Can't I just paste the review into ChatGPT and get an answer?"
You can. And the result will be exactly what you'd expect — one-off, contextless, with no understanding of the business. Here are the concrete reasons a bare model doesn't work for the review-reply task:
ChatGPT doesn't know your return policy, warranty terms, catalogue or the history of issues with a specific product. It doesn't know that 18% of reviews on a particular pair of sneakers complain that they run small. It will write "we hear about this for the first time" where the right answer is "yes, we know about this — we recommend going one size up".
Every ChatGPT request is a new context from scratch. You can't set a single tone of voice for the whole shop, can't upload a knowledge base, can't configure rules. Every time you copy a review, paste a prompt, edit the result, copy it back. At 50 reviews a day this turns into hell.
The model won't tell you: "73% of your replies are the same copy-paste, every other one is full of bureaucratic phrasing, and your average response time on negative reviews is 28 hours — that's killing conversion." For that you need a separate analytical layer — and we built one.
To automate the process you need to pull reviews via API, publish answers via API, manage roles, set up auto-publish rules. ChatGPT is a text box, not a business tool.
That's exactly why niche AI agents are a market category in their own right. A bare model is a brain without a body. What businesses need is a ready-made agent with hands, feet and memory: integrations, a knowledge base, analytics, a UI and access control.
Frontend — a Next.js app built on top of the Directual starter template. A three-column UI with SSE streaming.
Backend — Directual: pipeline orchestration, marketplace integrations, data storage, user and role management.
AI agent — a prompt-driven architecture: a large structured system prompt + dynamic context assembled by the backend.
LLM provider — GigaChat by Sber. For Russian B2B the choice is obvious:
Pre-analyzer — a separate Python service for deterministic analysis of reviews and replies. It computes everything that can be computed without an LLM.
Let's go through each component.
The frontend is built on Next.js + Directual Starter Template — our starter kit which already ships with auth (magic link, password reset), a WebSocket connection to Directual, SSE streaming and a basic dashboard.
The template is a bridge between vibe coding and a serious backend. You can throw the frontend together quickly — Cursor, Copilot, whatever — while all the business logic, data, integrations and orchestration live on Directual. This is a fundamentally different posture from "everything on the frontend": here the frontend is thin and the brains live on the backend.
Frontend stack:
The key UX decision is three columns:
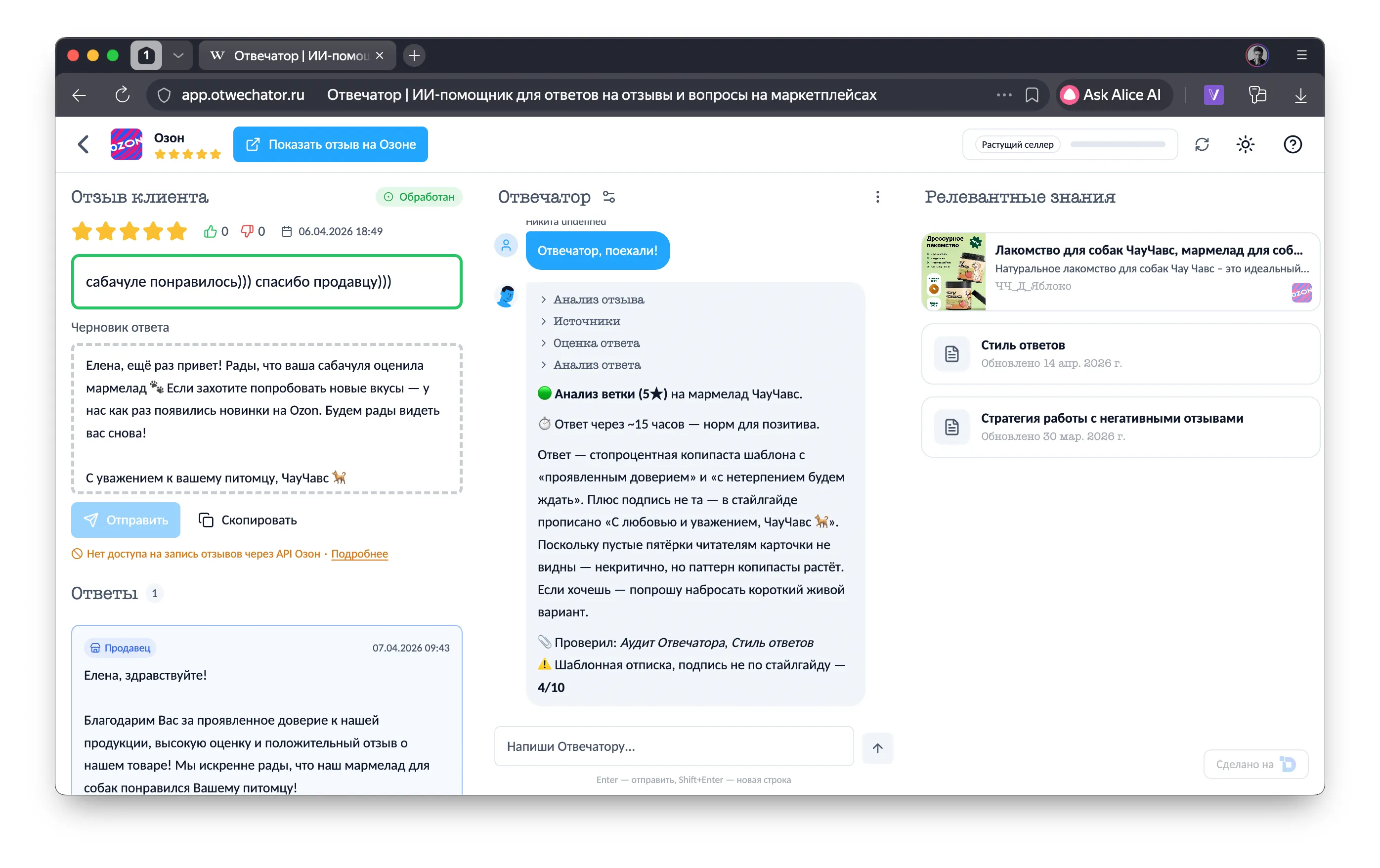
The LLM response streams over SSE in real time — the seller watches the agent "think" (extended thinking) and "type" the answer. It's not just a nice touch; it lowers anxiety: it's obvious the agent is working, not stuck.
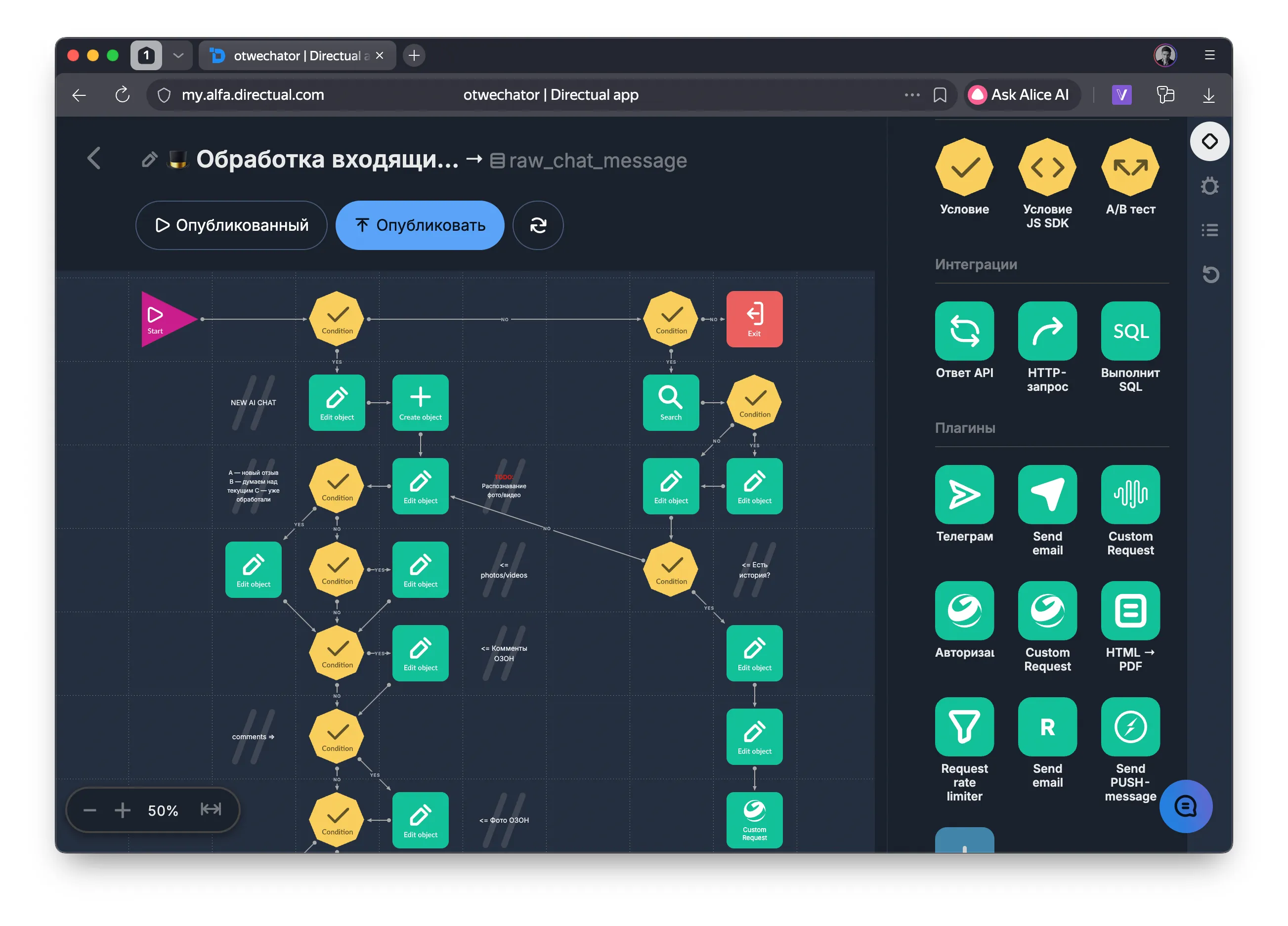
The entire Otwechator backend is Directual. Not "Directual + five other services". Directual is the only platform that orchestrates the whole pipeline from receiving a review to publishing a reply.
Marketplace integrations — Directual pulls reviews via API from Ozon, Wildberries, Yandex Market and Avito. New reviews appear in the system automatically. Replies are published back through the marketplaces' APIs.
Data storage — every review, draft, chat, project, user and document lives in Directual's built-in database. Each project is its own namespace with full data isolation.
Context assembly for the LLM — on every request the backend gathers the full context: review text, comments, product card, seller documents, pre-analysis results, chat history. All of it is packed into a structured prompt.
LLM call and streaming — Directual hits the model over HTTP, receives the SSE stream and proxies it to the frontend without buffering.
Roles and permissions — the built-in role system controls who can do what: who can publish replies, who can only view drafts, which reviews can be posted on (more on this below).
Webhooks and notifications — new reviews, status changes, analysis results — these are all events that Directual handles via scenarios and pushes to the client over WebSocket.
We could have written the backend in Node.js or Python — and burned three months on infrastructure instead of product. Directual let us focus on business logic:
Streaming deserves its own section, because this is the thing that sets Directual apart from the rest of the low-code market.
An AI agent that goes silent for 10 seconds and then dumps a wall of text is bad UX. The user needs to see the answer being generated in real time. That requires SSE (Server-Sent Events) — a streaming channel from the server to the client.
Directual supports SSE natively, via directual-js-api. And it supports it in two modes — and that's the part that matters.
The simple flavour: send a POST request, get back an SSE stream. Request → stream. That's exactly how reply generation works in Otwechator: the frontend pushes a request, Directual assembles context, calls the LLM and proxies the SSE stream straight to the client.
Client → POST /stream/{structure}/{method} → Directual → LLM
◀── SSE: content_block_delta... ──◀── GigaChat stream ──◀
Now this is the serious one. A two-phase mechanism:
streamIdstreamId over GETClient → POST /stream/init/{structure}/{method}
◀── { streamId: "abc-123" }
Client → GET /stream/subscribe/abc-123
◀── SSE: data as it becomes available
Why two phases? Because in real agentic systems the process that initiates the stream and the process that consumes it are often different. A backend scenario kicks off generation (init), gets a streamId, stores it in the database — and a separate process (frontend, another scenario, mobile app) subscribes to the result.
This is critical for cloud-based autonomous agents. Picture an agentic loop running on a server: the agent calls a tool → gets a result → thinks → calls the next tool. Every step is a separate LLM call, every call is a stream. Init + Subscribe decouples execution from connection: the agent runs in the background, and the client can subscribe to the stream at any moment, reconnect after a drop, or even subscribe after the fact.
No other low-code/no-code tool offers this. n8n, Make, Zapier — all request/response. Bubble, Xano — no SSE support at all. Directual is the only platform where LLM streaming is a native, production-grade feature with two operating modes.
In Otwechator we use mode one (single-request) — because we have a prompt-driven architecture with a single call. But the infrastructure for a full agentic loop is already there, and for the next generation of products built on Directual it will matter.
This is probably the most interesting part. While everyone around us is building agentic loops with tool calls, we picked a prompt-driven approach. Here's why.
In an agentic loop the model decides which tools to invoke: search_knowledge, get_product_info, get_similar_reviews. Sounds cool — but for the review-reply task it's overkill:
Instead of letting the agent hunt for information, the backend assembles everything up front and injects it into the prompt. The model gets the full context in one shot and emits a structured response.
┌──────────────────────────────────────────────────────┐
│ system prompt: ~600 lines of instructions (static) │
├──────────────────────────────────────────────────────┤
│ user message (dynamic, built by the backend): │
│ <task>A</task> │
│ <review>review text, rating, date...</review> │
│ <comments>comment history</comments> │
│ <product_contexts>product card</product_contexts> │
│ <seller_docs>policies, tone of voice</seller_docs> │
│ <seller_analysis>reply audit</seller_analysis> │
├──────────────────────────────────────────────────────┤
│ assistant: structured response │
│ <review_analysis>review analysis</review_analysis> │
│ <response_strategy>reply strategy</strategy> │
│ <draft>final reply text</draft> │
│ <chat_message>message for the seller</chat_message>│
└──────────────────────────────────────────────────────┘
The system prompt isn't "you're an assistant, answer reviews". It's a detailed behaviour specification — about 600 lines, marked up in XML. The document covers:
A key architectural decision is using XML tags as the protocol between the LLM and the UI. The model responds in a structured way:
<review_analysis> — situation analysis<sources_used> — which documents were used<response_strategy> — reply strategy<draft> — final reply text<chat_message> — message to the seller in chatThe frontend parses these tags out of the SSE stream in real time and routes them to the right UI sections: draft to the left, chat message to the chat, analysis to a collapsible block. This is at the same time:
Each project in Otwechator is its own workspace with its own knowledge base. The seller uploads:
All of that lives in the Directual database, and on every request the backend pulls the relevant documents and injects them into the prompt. The agent knows your business not because it's been "trained" — but because it gets fresh context on every call.
One of the most powerful features is the Otwechator Audit. It's a deterministic Python service that analyses the seller's existing reviews and replies before the LLM ever runs.
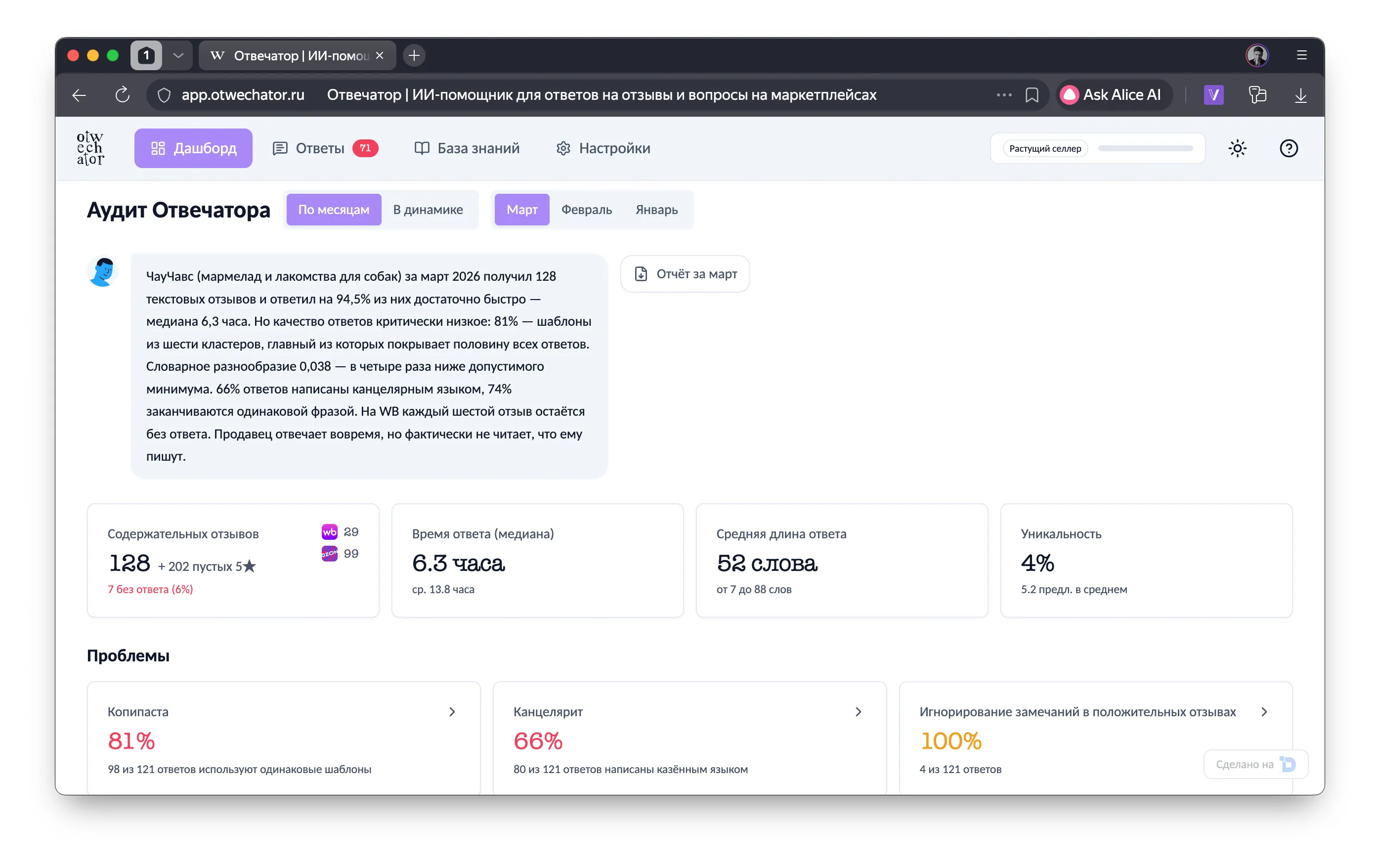
The job: understand how the seller has been answering, find systemic problems, surface anti-patterns. We could have done it inside the LLM — but why burn tokens on something that's perfectly computable algorithmically?
The pre-analyzer is a FastAPI service in Python. Zero LLM calls. Everything runs locally: TF-IDF, cosine similarity, DBSCAN clustering, morphological analysis via pymorphy3. Pure math.
The seller's reviews and replies for the past month are pulled via API and sent to the pre-analyzer in a batch. It processes anywhere from 10 to 2,000 review/reply pairs and produces a report:
12 analysis modules:
The pre-analysis result is injected into the prompt as <seller_analysis> — and the agent gets the full picture:
Thanks to this the agent doesn't repeat the seller's mistakes. If the seller wrote "Thank you for your feedback" in 73% of replies — the agent will pick a different phrasing. If complaints about sneakers running small are systemic (18% of all reviews) — the agent won't write "we hear about this for the first time".
The result is cached and reused for every review on that product — there's no point recomputing it for every single review.
The seller opens a review and hits "Go!". Then:
Total: ~7–13K input tokens, ~1–2K output. One call. 2–5 seconds.
The seller writes in the chat: "Make it shorter" or "Add something about the warranty" or "Drop the apologies, this isn't our fault."
The backend appends the message to the chat history, plugs in the current draft, refreshes the context (if the documents changed) — and again one LLM call. The model sees the whole history plus the seller's edit and emits an updated draft.
The seller has already replied on the marketplace. Otwechator analyses the thread and grades it honestly across 11 criteria: response speed, specificity, brevity, bureaucratic phrasing, tone, completeness, promises, effect on the reader, escalation to DMs, copy-paste, contextualization. Scores from 1 to 10 — no inflation.
If the score is low (1–4), it suggests a follow-up comment the seller can publish next to repair the situation. Not "rewrite the reply" (you can't edit it any more) but "add an addendum".
One of the concepts we're most proud of: the Otwechator Agent is a full team member.
A project has a team: the shop owner, managers, assistants. Each gets permissions — who can view, who can edit, who can publish replies.
And here's the key bit: the agent is also a participant with configurable permissions. It works within the same boundaries as humans.
You can configure:
This lets you shape the workflow around the actual business: more freedom for senior managers, restrictions for juniors, dedicated rules for the agent. Everyone works in the same UI under the same rules.
| Component | Technology | Purpose |
|---|---|---|
| Backend | Directual | Orchestration, data, API, integrations, permissions |
| Frontend | Next.js + Directual Starter Template | UI, SSE streaming, WebSocket |
| UI components | shadcn/ui + Tailwind CSS | Fast UI assembly |
| LLM | GigaChat (by Sber) | Russian infrastructure, native-grade Russian, no sanction risk, ruble billing |
| Pre-analyzer | Python, FastAPI, scikit-learn, pymorphy3 | Deterministic analysis without an LLM |
| Streaming | SSE (Server-Sent Events) | Streaming LLM responses |
| Notifications | Socket.IO | Realtime status updates |
At 1,000 reviews a day — $10–30 of LLM spend. A human manager costs more.
For those interested in the implementation details on the platform:
Monetization is a separate story. Otwechator's billing is a YooKassa + Directual combo. YooKassa accepts the money, while all the accounting, subscription and balance logic lives on Directual:
YooKassa handles money intake — everything else (subscription logic, balances, charges, notifications) lives on Directual as ordinary business logic. No custom billing microservice.
Directual auto-generates a REST API for every structure. The frontend talks to the backend through standard GET/POST requests and SSE streams. All of it works through a single auth point — no separate auth service.
We're building a product on our own platform — and it's not just dogfooding for the sake of it. Directual genuinely covers every need Otwechator has:
Complex backend without code — orchestration of the generation pipeline, integrations with four marketplaces, streaming, webhooks, CRON jobs. All of it via visual scenarios.
Plug into any LLM — GigaChat, YandexGPT, Claude, GPT, Gemini — through standard HTTP requests. We're not locked into a single provider; we can switch models depending on the task, the budget and regulatory requirements.
Native SSE streaming — two modes: single-request for simple pipelines, init + subscribe for autonomous agents. No low-code competitor offers this — details in directual-js-api.
Billing as business logic — payment intake, subscriptions, token and reply accounting — all through scenarios and data structures, no external billing services.
Roles and permissions out of the box — a permission system that let us implement the "agent as a team member" concept without writing any auth logic.
Cloud — we don't think about servers. Otwechator processes thousands of reviews a day, Directual scales automatically.
Development speed — from idea to MVP — weeks, not months. Every change in business logic happens in the visual builder, no backend deploys.
Otwechator is an example of what happens when a niche AI agent is built on the right infrastructure:
If you sell on marketplaces and you're tired of templated replies — give Otwechator a try.
If you want to build your own AI agent for a different niche — start with Directual. Free AI Agents course — 60 minutes, and you'll have built your first agent with a RAG system.

Join 22,000+ no-coders using Directual and create something you can be proud of—both faster and cheaper than ever before. It's easy to start thanks to the visual development UI, and just as easy to scale with powerful, enterprise-grade databases and backend.



